Minjae Lee
Wordle Pipeline: Project Overview
Data pipeline to process New York Times Wordle data.
Despite Wordle existing as a game for many years, a perfect strategy to beat the daily game has yet to be discovered.
This project aims to provide a data-driven approach to the game by preparing data extracted from Twitter posts sharing each individual's worder score.
Detailed documentation is available on my Github Project Page and the Project Dashboard is available below.
Architecture
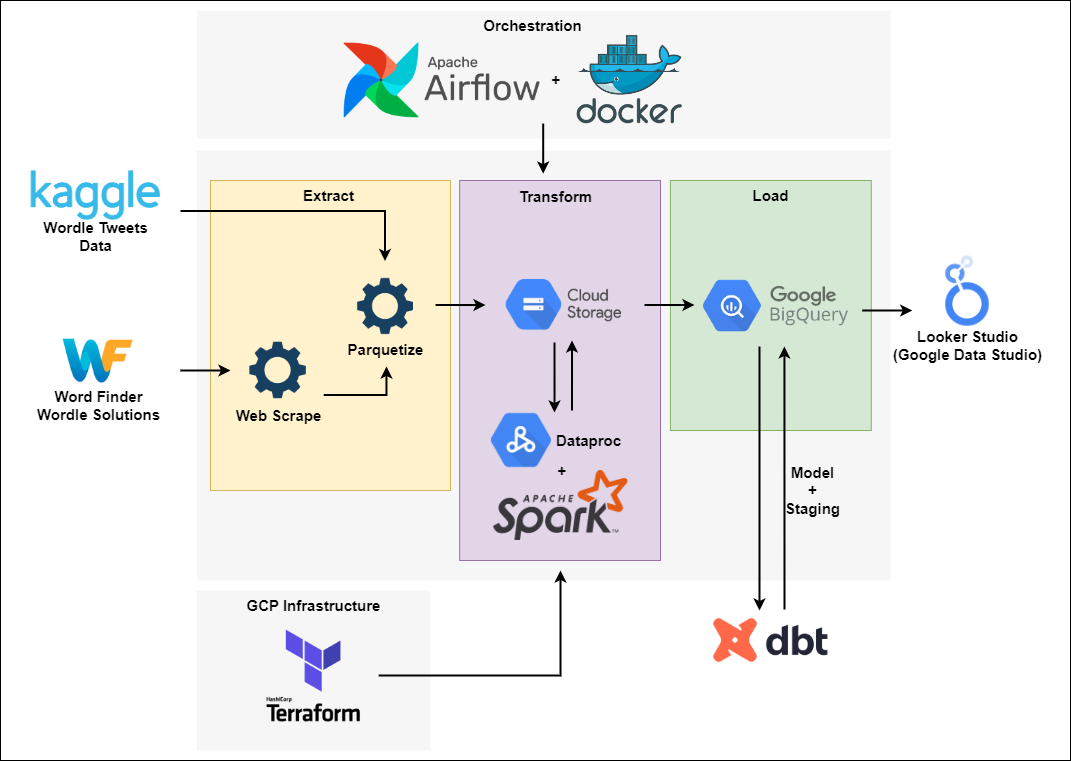
- Create GCP Infrastructure with Terraform
- Extract Wordle Tweets Data + scrape Wordle Solutions Data from the web
- Parquetize data
- Load raw data to GCS Bucket
- Transform with Spark using Dataproc
- Load to Bigquery
- Model and Stage data with DBT
- Visualization with Looker Studio
My Projects

Wordle Pipeline
The project is a pipeline which processes New York Times Wordle data from Twitter to provide insight on Wordle statistics. The data is transformed and orchestrated using Docker, Spark, Airflow, and dbt. The project is hosted on GCP and is loaded into Looker Studio for visualization.
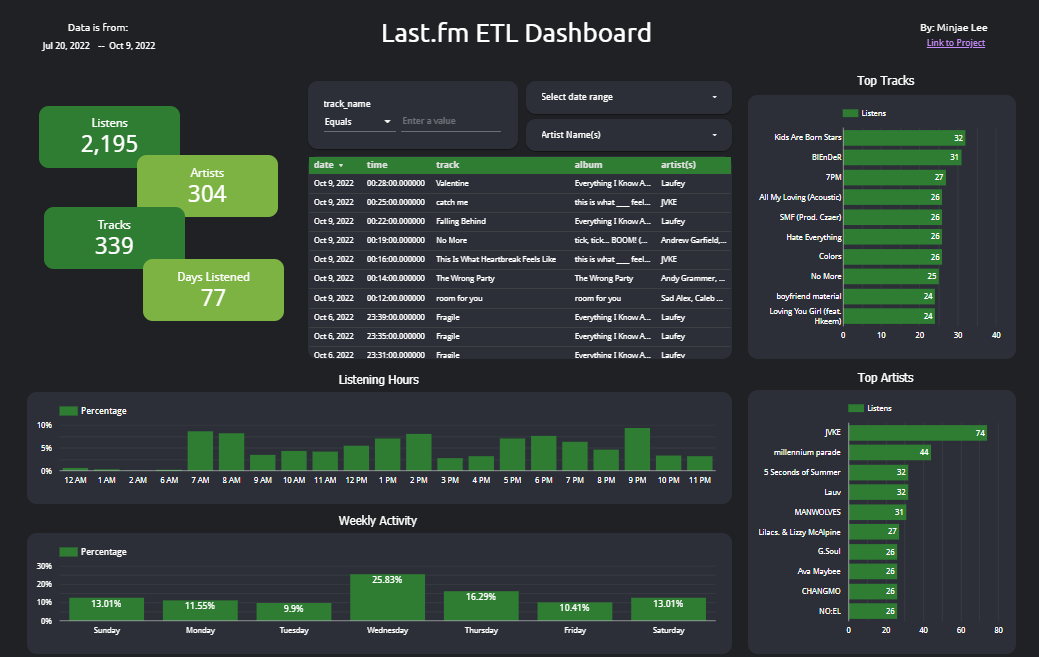
Music Listening History ETL Pipeline
The project is an ETL pipeline which processes music listening data from Last.fm API to provide insight on listening activity. The data is transformed and orchestrated into Kimball's star schema model using Python, SQL, and Airflow. The data is then loaded into Google Data Studio for visualization.